이전 기사 보러가기 -> 딥러닝? 머신러닝? 차이가 뭐예요?
원제 : 딥러닝, 머신러닝의 차이점은? - 2 -
2. 머신러닝과 딥러닝의 비교
1장에서는 머신러닝과 딥러닝의 대략적인 개요를 살펴보았습니다. 이제 우리는 특히나 중요한 몇 가지 포인트들과 두 방법론의 테크닉 차이를 비교해보겠습니다.
2.1 데이터 의존도(Data dependencies)
딥러닝과 전통적이 머신러닝에 있어 가장 큰 차이점은 데이터 양에 따른 성능입니다. 데이터 양이 작다면 딥러닝 알고리즘의 성능은 잘 나오지 않습니다. 왜냐하면 딥러닝 알고리즘은 어떤 과제를 이해하기 위해서 매우 큰 데이터가 필요하기 때문입니다. 그와 반면에, 똑같은 시나리오에서는 수작업이 들어간 전통적인 머신러닝 알고리즘이 더 우세합니다.

2.2 하드웨어 의존도(Hardware dependencies)
딥러닝 알고리즘은 고사양 machine이 많은 부분을 좌지우지합니다. 그와 반대로 머신러닝은 저사양 machine에서도 실행이 가능합니다. 이 이유는 무엇일까요? 딥러닝 알고리즘의 요구사항(requirements)는 GPU가 포함되기 때문입니다. GPU는 작업에서 숫자 계산을 담당합니다. 딥러닝 알고리즘은 본질적으로 많은 양의 행렬 곱셈(matrix multiplication)을 수행합니다. 이 작업은 GPU의 구축 목적과 같기 때문에, GPU를 사용하면 보다 효율적으로 최적화 할 수 있습니다.
2.3 Feature engineering
Feature engineering은 데이터 복잡성을 줄이고 학습 알고리즘에서 패턴을 보다 잘 보이게 하는 과정입니다. 이 과정은 시간과 전문가가 필요하다는 관점에서 어렵고 비쌉니다. 머신러닝의 경우, 대부분의 적용된 변수(feature)는 전문가가 식별한 다음 정보 영역 및 데이터 유형별로 손으로 코딩해야 합니다.
*참고. 쉽게 설명드리자면, A은행에서 신용등급을 평가하는 모형을 만든다고 가정해봅시다. A은행에서 가지고 있는 데이터를 활용해 머신러닝 알고리즘에 대입해 보았더니 대략 50개 정도의 변수가 유의미하다고 내뱉어졌습니다. 하지만 우리는 50개 변수 모두 활용할 수 없습니다. 비즈니스적 요건이나 금융당국의 규제에 따라 제거되어야 하는 변수들이 있을 수 있겠지요. 예를 들자면, 학력 정보(중졸/고졸/대졸 등)나 성별 정보입니다. 이런 경우가 전문가가 직접 확인하고 걸러내는 작업입니다.
예를 들어, 변수가 픽셀값, 모양, 텍스쳐, 위치, 방향이라고 가정해봅시다. 대부분의 머신러닝 알고리즘 성능은 변수가 어느 정도로 정확히 식별되고 추출되는가에 달려 있습니다.
딥러닝 알고리즘은 high-level features를 학습합니다.
(고차원적인 변수로 이해하시면 될 것 같습니다.)
이 부분이 딥러닝이 머신러닝보다 좀 더 앞서 있다라는 특징입니다. 따라서 딥러닝은 모든 과제에서 새로운 변수 추출이라는 작업을 줄여줍니다. Convolutional Neural Network의 경우, 초기 layer에서는 이미지의 edge나 line같은 low-level features를 학습하고 그 다음 이미지의 high-level 표현을 학습합니다.
(그림과 함께 보시면 이해에 도움이 되실 것입니다.)

2.4 문제 해결 접근법(Problem Solving approach)
전통적인 머신러닝 알고리즘으로 문제를 해결할 때에는 주로 문제를 여러 개의 파트로 쪼갠 후, 각각에 대한 답을 구하고 그 결과를 합치는 방법을 추천합니다. 딥러닝은 그와 대비되게 end-to-end방식으로 문제를 해결합니다. (end-to-end가 명확하지 않으니 다음 예제를 참고하십시오.)
예제를 들어보겠습니다.
만약 당신이 사물 인지 작업을 진행해야 한다고 가정해봅시다. 그리고 사물이 무엇인지 그리고 사진 어디에 해당 사물이 위치하고 있는지를 구별해내는 것이 과제입니다.

대게의 머신러닝 접근 방법은 문제를 1.사물 탐지/2.사물 인지 두 개의 step으로 나눌 것입니다. 먼저, ‘grabcut’과 같은 경계 탐지 알고리즘(bound box detection algorithm)을 사용하여 이미지를 훑어보고 가능한 모든 객체를 찾습니다. 그리고 발견된 모든 개체들 중에서 HOG가있는 SVM(Support Vector Machine)과 같은 객체 인식 알고리즘을 사용하여 관련 객체를 인식합니다.
반면, 딥러닝 접근방법은 end-to-end입니다. 예를들어 YOLO net(딥러닝 알고리즘 중 하나)에서 이미지를 전달하면 객체의 이름과 함께 위치가 표시됩니다.
2.5 실행 시간(Execution time)
딥러닝 알고리즘은 훈련(train) 시간이 굉장히 오래 걸립니다. 딥러닝 알고리즘에서는 다른 알고리즘 대비 변수가 너무 많기 때문입니다. 최신 딥러닝 알고리즘인 ResNet의경우 training이 약 2주 정도 걸립니다. 하지만 머신러닝은 수 초에서 수 시간으로 비교적 적은 시간이 걸립니다. test에서의 시간은 반대로 딥러닝 알고리즘에서 훨씬 적은 시간이 소요됩니다.
반면, k-nearest neighbors (머신러닝 알고리즘의 일종)의 경우 데이터 크기가 커질수록 테스트 시간이 길어집니다. 이것은 일부 머신러닝 알고리즘은 너무 작은 테스트 시간을 갖고 있기 때문에 모든 머신러닝 알고리즘이 그렇다고 볼 수 는 없습니다.
* 모델링에는 train set과 test set이 존재합니다. 단어에서 얼추 유추하셨을 수 있겠지만, 우리가 일반적으로 실제값에 가까운 모델을 만들기 위해 활용되는 데이터셋은 train set이고, 이 train set으로부터 적합된 결과가 타당하지 검사할 때 쓰는 데이터가 test set입니다. 정리하자면, linear model(y = ax +b)에서 train set으로 input 변수 x에 해당하는 적절한 a,b 값을 찾았다면, test set의 input 변수 x값으로 최종 성능이 train set의 성능과 유사하게 산출되는지 검증한다고 보시면 됩니다.
2.6 해석력(Interpretability)
마지막으로 머신러닝과 딥러닝을 비교할 수 있는 또 다른 요인으로는 ‘해석력’을 들 수 있습니다. 이 요인이 딥러닝이 실제 실무에 쓰려 마음 먹으면 그 전에 10번 정도는 고민하는 이유입니다.
예제를 들어볼게요. 에세이의 점수를 자동으로 매기기 위해 딥러닝 알고리즘을 활용했다고 해봅시다. 성능은 거의 사람이 한 것과 유사할 정도로 뛰어납니다. 하지만, 아주 치명적인 문제가 있긴 합니다. 왜 이 점수가 부여됐는지는 알 수 없기 때문입니다. 사실 수학적으로 딥러닝의 어느 노드가 활성화되었는지를 알 수 있긴 하지만, 우리는 거기에 어떤 뉴런이 만들어 졌는지, 그리고 이들 뉴런 레이어가 전제적으로는 무엇을 하고 있는지 알지 못합니다. 그래서 우리는 결과를 해석하지 못합니다.
하지만, 의사결정나무(decesion tree)와 같은 머신러닝 알고리즘은 왜 선택됐는지 명확한 rule이 제공되기 때문에 해석하기가 특히 쉽습니다. 따라서 ‘해석’이 필요한 산업에서는 의사결정나무나 선형회귀모형, 로지스틱회귀모형이 활용됩니다.
반면에 의사 결정 트리와 같은 기계 학습 알고리즘은 왜 선택한 알고리즘을 선택했는지에 대한 명확한 규칙을 제공하므로 배후의 추론을 해석하기가 특히 쉽습니다. 따라서 결정 트리 및 선형 / 로지스틱 회귀와 같은 알고리즘은 주로 업계에서 해석 가능성을 위해 사용됩니다.
3. 머신러닝과 딥러닝은 현재 어디서 쓰이고 있나?
컴퓨터 비전: 자동차 번호판 인식, 안면인식 등

위의 그림은 머신러닝이 활용되는 사업들을 정리해놓은 자료입니다. 기계 지능이라는 더 광범위한 주제 기반이긴 하지만요.
머신러닝/딥러닝 활용의 대표적인 회사가 구글입니다.
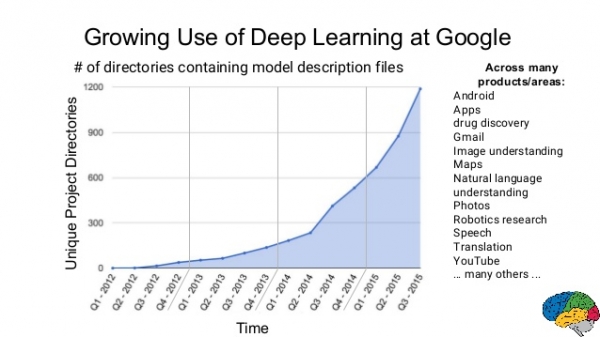
위의 그림을 보면 구글이 얼마나 다양한 상품에 머신러닝을 활용하는지 알 수 있을 것입니다. 이렇게 머신러닝과 딥러닝의 활용 영역은 무수히 많습니다. 당신이 할 일은 결국 적시의 기회를 찾는 것이죠!
본 글은 https://www.analyticsvidhya.com/blog/2017/04/comparison-between-deep-learning-machine-learning/를 번역+약간의 의역을 하였습니다. 중간중간 저의 개별적인 설명은 파란색 글씨로 써두었습니다.
<외부 기고 콘텐츠는 이웃집과학자 공식 입장과 다를 수 있습니다>
월급쟁이(hwpark0502@gmail.com)
늘 재밌게 살고싶은 월급쟁이의 데이터 이야기
원문 출처 : https://brunch.co.kr/@itschloe1/8
