이전 글 보기 -> 특정 시기, 어떤 제품이 잘 팔릴까?
원제 : Linear Regression의 쉬운 풀이 - 2 -
Ridge와 Lasso Regression을 이해하기 위한 Preview
Keywords
#예측모형, #선형회귀모형, #linearregression, #costfunction, #GradientDescent, #R-squared, #AdjustedR-squared, #Python
-------------------------------------------------------------------------------
[목차]
1. Simple models for Predictio
2. Linear Regression
3. The Line of Best Fit
4. Gradient Descent
5. Using Linear Regression for Prediction
6. Evaluate your Model - R square and Adjusted R squared
7. Using all the features for Prediction
8. Polynomial Regression
9. Bias and Variance
10. Regularization
11. Ridge Regression
12. Lasso Regression
13. ElasticNet Regression
-------------------------------------------------------------------------------
4. Gradient Descent
다음 식의 최소 값을 찾아봅시다.
Y = 5x + 4x^2
수학적으로 우리는 x에 대해 derivate(미분)을 취하게 되고 결과값이 0인 x값을 찾을 것입니다. 그리고 해당 x값을 넣어, (x,y)를 찾게 되겠지요. Gradient descent도 이와 비슷한 방법으로 작동합니다. Gradient descent는 비용 함수가 가장 최소화 될 수 있는 점을 찾기 위해 반복적으로 Θ값을 업데이트 합니다.
5. Using Linear Regression for Prediction
이제 다시 상점 판매량 예측 문제로 돌아가서, 우리가 배운 Linear Regression을 활용해보도록 하겠습니다.
Model 3 - 선형회귀모형(Linear Regression) 대입하기
이전 예제를 통해 맞는 변수를 이용하는 것이 모형의 정확성을 개선시킬 수 있는 방법임을 알 수 있습니다. 그렇다면 이번엔 2개의 features를 사용해봅시다. 'MRP'와 '매장설립일'로 판매량을 추측해봅시다.
Python을 이용해 이 두 개의 features에 대한 linear regression model을 만들어 봅시다.


결과를 보면 MRP는 높은 계수(Coefficient Estimate)를 나타내고 있기 때문에 상품이 높은 가격을 가질수록 판매량 성적은 더 좋은 것임을 알 수 있습니다.
6. Evaluate your Model - R square and Adjusted R squared
모형이 얼마나 정확할까? 우리가 확인할 수 있는 평가 방법이 있을까요? 네, 사실 우리는 R-Square라는 측정값을 알고 있습니다.
R-Square는 Y(dependent variable)의 총 변동량이 X(independent variable)의 변동량으로 설명되는 양을 결정합니다. 수학적으로는 이렇게 나타낼 수 있습니다.

R-square값은 항상 0에서 1사이의 값을 나타냅니다. 0은 모델이 target 변수(Y)를 전혀 설명하지 못한다라는 뜻이고, 1은 target 변수를 완전히 설명한다라는 뜻입니다.
위의 모델의 R-square값을 확인해 봅시다.

이 경우, R²은 33%입니다. 33%의 판매량 변동성이 매장설립년도와 MRP로 설명된다라는 뜻입니다. 다르게 표현하자면, 만일 당신이 설립년도와 MRP를 알고 있다면 당신은 판매량을 정확히 예측하기 위해 33%의 정보를 가졌다라고 보시면 됩니다.
만일 여기서 제가 또 다른 변수(feature)를 기존 model에 넣게 된다면 모형은 더 실제값과 가까워질까요? R-square값은 증가하게 될까요?
Model 4 - 더 많은 변수를 활용한 Linear regression
우리는 물건 판매량 예측 모형을 만들 때 변수 한 개를 활용했을 때보다 두 개를 활용한 경우가 성능면에서 더 우수한 것을 확인했었습니다.
그렇다면 이번에는 weight라는 또 다른 변수를 넣어보겠습니다. 3개의 변수로 regression model을 마찬가지로 만들어보죠.

에러가 나오네요. 에러 문장을 보니 weight라는 컬럼에 missing value가 있는 것 같습니다. 그렇다면 빈 값은 전체(non-null)의 평균으로 채워넣어보죠.



MSE는 1,853,431로 이전 모델보다 줄어들었고, R-square값도 증가하였습니다. 그렇다면 item weight이라는 변수의 추가가 우리 모형에 유용하다는 뜻일까요?
Adjusted R-square
R-squared의 유일한 단점은 새로운 예측 변수(X)가 추가되면, R²는 절대 감소하지 않고, 늘어나거나 일정하게 유지됩니다. 모델의 복잡성이 증가합에 따라 모형이 점점 정확해진다고 판단할 수 없습니다.
따라서 우리는 "Adjusted R-Square"값을 이용합니다.
Adjusted R-Square는 x변수의 갯수에 맞게 조정된 R-Square의 변형값입니다. 이 값은 모델의 자유도를 통합하고, 새로운 변수가 모델 정확도를 향상시키는데 기여할 때만 증가합니다.

where
R² = 샘플의 R-square
p = predictors(변수)의 갯수
N = 샘플 사이즈
7. Using all the features for Prediction
이제 모든 변수를 포함한 model를 만들어봅시다. 이번 모델링에서 저는 연속형 변수만을 쓰려 노력했습니다. 왜냐하면 범주형 변수의 경우 linear regression에 반영하려면 사전 데이터 처리 작업이 필요하기 때문입니다. 이 처리 방법은 여러가지가 있지만, 저는 one hot encoding(범주형 변수의 내용들을 각각 변수화하는 방법, 즉 dummy variable을 생성)만을 썼습니다. 그 외에도 아울렛 사이즈 컬럼의 missing value값도 처리하였습니다.
Data pre-processing steps for regression model

Building the model

보시다시피 MSE와 R-Square값의 명확한 개선이 있기에 현재 모형이 이전보다 훨씬 더 실제 값과 근접하다고 볼 수 있습니다.
모형에 적합한 변수 선택하기
높은 차원의 데이터셋을 가지고 있을 경우, 이 모든 변수를 전부다 활용한다는 건 굉장히 비효율적일 것입니다. 왜냐하면 그 중의 몇은 서로 중복 정보를 포함하고 있기 때문이죠. 그래서 우리는 정확한 모델을 제공하면서도 종속 변수를 잘 설명할 수 있는 적합한 변수를 선택해야 합니다. 모델에 적합한 변수를 선택하는데에 있어서는 여러 가지 방법이 있습니다. 첫번째는 비즈니스적 이해 및 업무 지식입니다. 예를 들어 판매량을 예측할 때에 마케팅이 판매의 중요한 영향을 미치고 또한 중요한 변수로써 작용한다는 것을 우리는 알고 있습니다. 그리고 우리가 선택하는 변수들이 서로 correlate이 되어서는 안됨을 유의해야 합니다.
수동으로 변수를 일일이 선택하는 것 대신, 우리는 forward 또는 backward selection으로 이 과정을 자동화 할 수 있습니다. (forward selection와 backward selection을 결합한 stepwise selection 도 존재합니다.) Forward Selection은 모델의 가장 중요한 변수부터 시작하여 그 다음 중요도에 따라 하나 하나씩 넣어보는 것을 의미하고 Bacward elimination은 모든 변수를 일단 다 넣고 가장 중요하지 않은 변수부터 차례 차례 빼내는 변수 선택 과정입니다. (그렇다면 stepwise는 변수를 넣고 빼고를 반복하면서, 가장 최적의 조합을 찾는 것이겠죠?) 선택의 기준은 통계값인 R-square, t-stat이 있겠습니다.
Regression Plots 해석하기
예측값과 잔차의 관계를 나타낸 plot을 확인해보십시오.

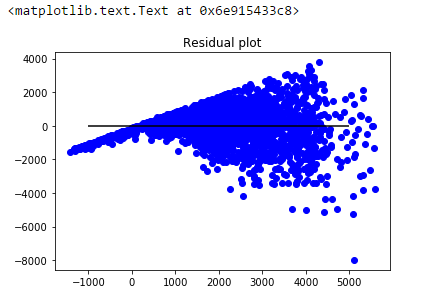
plot에서 깔대기 모양의 그림을 볼 수 있습니다. 이 모양은 Heteroskedasticity(이분산성)를 나타냅니다. 오차항에서 변화하는(non-constant) 분산이 나타나면 이분산성이 생깁니다. 그림에서 오차항의 변동이 일정하지 않음을 분명히 알 수 있습니다.
일반적으로 non-constant variance는 특이치(outliers)나 extreme leverage values가 있을 때 발생합니다. 이런 극단치의 값이 너무 큰 가중치를 가지게되면서 모델의 성능에 불균형적인 영향을 미치게 됩니다. 이런 현상이 발생하게 될 때에, out-of-sample의 값 예측에 대한 신뢰 구간은 비현실적으로 넓거나 좁아지는 경향이 있습니다.
*참고. out-of-sample이란?
우리가 모형을 만들 때에 선택되는 sample에는 전체 집단 중 일정 부분을 떼어낸 것이기 때문에 bias가 존재할 수 있습니다. 따라서 그 sample로 linear regression을 만든다고 하면 sample에 국한된 선형회귀모형이 만들어질수도 있겠죠? 이를 확인하기 위해서 전체 집단에서 제가 모형을 만들기 위해 선택했던 sample이 아닌 다른 sample, 즉 out-of-sample,을 이용하여 내가 만든 모형의 성능을 확인해보는 작업을 진행합니다.
우리는 이것을 residual vs fitted values plot으로 간단히 확인해 볼 수 있습니다. 만일 heteroskedasticity가 존재한다면, 위의 그림처럼 plot은 깔대기 모양의 패턴을 그릴 것입니다. 이는 모델에 서 잡히지 않은 데이터의 비선형성이 존재함을 나타내는 것입니다.
이러한 비선형 효과를 잡아내기 위해, 또 다른 regression이 있습니다. 바로 polynomial regression(다항 회귀)입니다. 함께 다음 장에서 알아보도록 하죠.
*본 글은 https://www.analyticsvidhya.com/blog/2017/06/a-comprehensive-guide-for-linear-ridge-and-lasso-regression/의 일부분을 번역+약간의 의역을 하였습니다. 중간중간 저의 개별적인 설명은파란색 글씨로 써두었습니다.
<외부 기고 콘텐츠는 이웃집과학자 공식 입장과 다를 수 있습니다>
월급쟁이(hwpark0502@gmail.com)
늘 재밌게 살고싶은 월급쟁이의 데이터 이야기
원문 출처 : https://brunch.co.kr/@itschloe1/9
