
성균관대학교 전자전기공학부 문태섭 교수 연구팀이 인공지능 분야에서 '적응형 평생학습 알고리즘 개발' 및 '설명가능 인공지능 방법의 취약성 규명'에 성공했습니다. 해당 연구는 <신경정보처리학회(Neural Information Processing Systems, NeurIPS)>에서 발표됐습니다.
새로운 알고리즘으로 성능↑

연구팀이 첫 번째로 개발한 적응형 평생학습 알고리즘은 '연속 학습' 문제를 다뤘습니다. 연속 학습(Continual learning)이란 순차적인 과제들을 계속해서 효율적으로 학습할 수 있는 과정을 말합니다. 기계학습 분야의 오랜 난제 중 하나죠. 연구팀은 베이지안 온라인 학습(Bayesian online learning)에 기반해 연구를 진행했습니다. 이를 통해 연구팀은 뉴럴 네트워크 모델 파라미터의 불확실성에 대한 정의를 새롭게 제시했습니다.
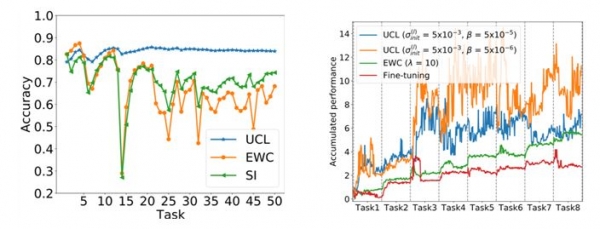
연구팀은 기존의 방법에 비해 약 30% 이상 적은 메모리를 사용했습니다. 동시에 새로운 개념을 익히고 과거의 지식을 점진적으로 망각해 갈 수 있는 알고리즘을 고안했는데요. 그 결과 연구팀의 알고리즘은 다양한 지도학습과 강화학습 상황에서 기존 알고리즘들을 압도하는 성능을 선보였다고 합니다.
적대적인 모델 조작, 결과 다르게 만들 수 있다

두 번째 연구는 '설명가능 인공지능 방법의 취약성 규명'입니다. 특징 지도(saliency-map) 기반의 딥러닝 해석 방법(interpretation method)은 최근 딥러닝 알고리즘의 예측 결과를 설명하는데 많이 사용되는데요. 연구팀은 특징 지도 기반의 딥러닝 해석 방법이 적대적인 모델 조작(adversarial model manipulation)에 매우 취약할 수 있음을 제시했습니다.
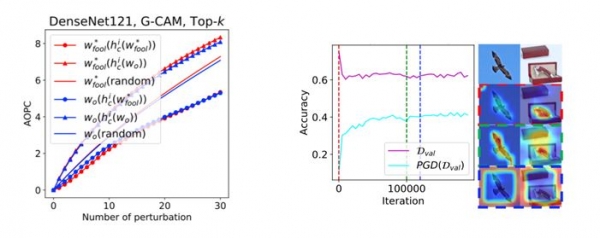
특징 지도 기반의 딥러닝 해석 방법들은 딥러닝 모델의 편향성 등을 탐지하는 데 특히나 중요하게 쓰일 수 있습니다. 적대적 사례(adversarial examples)는 인공지능에서 공격자가 높은 신뢰도를 보여주는 동시에 실수를 유발하도록 설계한 기계학습 모델에 입력하는 정보를 의미하는데요. 연구팀은 적대적 모델 조작을 가하게 되면 예측 정확도는 거의 변하지 않는 상태에서도 전혀 판이한 해석 결과가 나올 수 있음을 제시했습니다.

문태섭 교수는 "적응형 평생학습 알고리즘은 실제 AI기술을 사용하는 응용 분야에서 매우 필요로 하는 실용적인 기술이고, 향후 이 기술을 더 발전시킨다면 데이터가 순차적으로 확보될 수밖에 없는 응용 분야에 널리 쓰일 수 있는 파급력을 가졌다"고 말했습니다. 또한 문태섭 교수는 "설명가능 인공지능 기술의 취약성을 보인 연구는 향후 모델과 데이터에 가해지는 적대적인 공격에 더욱 강건한 인공지능 기술을 개발하는 데 필수적으로 고려해야 하는 기준을 제시했다"고 설명했습니다.
##참고자료##
- Ahn, Hongjoon, et al. "Uncertainty-based continual learning with adaptive regularization." Advances in Neural Information Processing Systems. 2019.
- Heo, Juyeon, Sunghwan Joo, and Taesup Moon. "Fooling Neural Network Interpretations via Adversarial Model Manipulation." arXiv preprint arXiv:1902.02041 (2019).
- OECD <사회 속의 인공지능>. OECD Publishing(2019).
