DGIST 정보통신융합전공 김예성 교수 연구팀은 빅데이터 연산에 있어 기존 연산 방식의 성능과 효율성을 개선한 메모리 기반의 연산 구조를 개발했습니다. 이번 연구는 기존 컴퓨터 시스템에서 발생하는 계산 병목을 찾아 이를 메모리 기반의 계산방식으로 변경·개선한 건데요. 향후 빅데이터 처리 분야에서 긍정적인 효과를 줄 수 있을 것으로 기대됩니다.

새로운 빅데이터 처리 기술
기존 컴퓨터 시스템은 메모리와 연산 장치(CPU)가 분리돼 있어, 빅데이터를 메모리와 CPU 간 송수신할 때 속도가 느려지는 병목현상이 종종 발생합니다. 이러한 기존 송수신 방식을 비지도 군집화 기계 학습(Unsupervised Clustering) 알고리즘이라 하며, 이는 데이터 처리에 있어 연산량 및 데이터 처리량이 기하급수적으로 늘어 연산에 문제점을 갖고 있습니다. 이와 관련해 김예성 교수 연구팀도 빅데이터 처리 과정에서의 메모리 대역폭 부족에 따른 병목 현상을 발견했습니다.
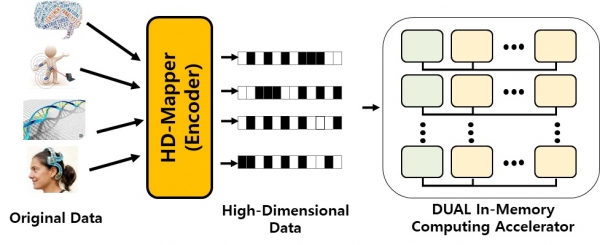
이에 따라 김예성 교수 연구팀은 부족한 메모리 대역폭 문제를 해결하고자 메모리 기반의 연산(In-Memory Computing) 컴퓨터 아키텍쳐를 활용했습니다. 기존의 아날로그 기반 하드웨어는 낮은 집적도 집로 인해 칩 공간 효율성이 떨어지는 문제가 있는데, 김예성 교수 연구팀이 개발한 컴퓨팅 시스템에서는 기존 아날로그 방식을 디지털화시켜 계산하는 새로운 메모리 설계방법을 적용했습니다. 참고로 집적도(Degree of Integration)란 하나의 칩에 논리 소자가 몇 개나 구성되어 있는지를 나타내는 정도인데요. 칩당 소자 수를 의미합니다.

여기에, 김예성 교수 연구팀은 초차원(Hyperdimensional) 컴퓨팅 알고리즘도 함께 적용했습니다. 초차원 컴퓨팅 알고리즘은 뇌의 계산 방식을 모방한 알고리즘으로, 숫자로 구성된 기존 데이터를 패턴화된 수많은 비트열로 재구성해 병렬 고속 연산이 가능합니다. 이로써 김예성 교수 연구팀은 메모리 기반 연산(In-Memory Computing) 아키텍쳐와 초차원(Hyperdimensional) 컴퓨팅 알고리즘을 통해 기존 대비 59배의 속도 향상과 251배의 향상된 에너지 효율성을 달성할 수 있었습니다.

DGIST 정보통신융합전공 김예성 교수는 "이번 연구를 통해 메모리와 연산장치 간의 병목현상을 제거하고 군집화 알고리즘 처리 성능을 최대 수십 배 가량 향상할 수 있다"며 "향후 빅데이터와 인공지능 분야 등에서의 효율적인 데이터 학습에 혁신을 가져올 수 있는 연구를 지속할 계획"이라고 말했습니다. 이번 연구의 논문은 국제 최우술 학술대회인 IEEE/ACM MICRO에 발표됐습니다.
##참고자료##
