원제 : Ridge와 Lasso Regression의 쉬운 풀이 - 2 -
왜 linear regression 대신 Ridge, Lasso를 선택할까
-------------------------------------------------------------------------------
[목차]
1. Simple models for Prediction
2. Linear Regression
3. The Line of Best Fit
4. Gradient Descent
5. Using Linear Regression for Prediction
6. Evaluate your Model - R square and Adjusted R squared
7. Using all the features for Prediction
8. Polynomial Regression
9. Bias and Variance
10. Regularization
11. Ridge Regression
12. Lasso Regression
13. ElasticNet Regression
-------------------------------------------------------------------------------
Keywords
#overfitting, #underfitting, #bias_and_variance, #regularization, #Ridge_regression, #Lasso_regression, #L1_regularizaiton, #L2_regularization, #ElasticNet_regression, #Python구현
11. Ridge Regression
우선은 여지껏 우리가 다뤘던 같은 데이터에 대해 Ridge regression이 linear regression보다 더 좋은 성능을 보이는지 확인해보겠습니다.

선형회귀모형 적합 결과의 성능값보다 살짝 더 높은 수준의 R-Square를 기록하네요. Ridge에서 hyperparameter인 alpha라는 값은 model에서 자동으로 학습되는 것이 아니라 수동으로 설정해야 한다는 점을 유의하세요. 여기에서 우리는 alpha값을 0.05라 가정하였고 또 다른 값을 적용하여 한 번 그려봅시다.

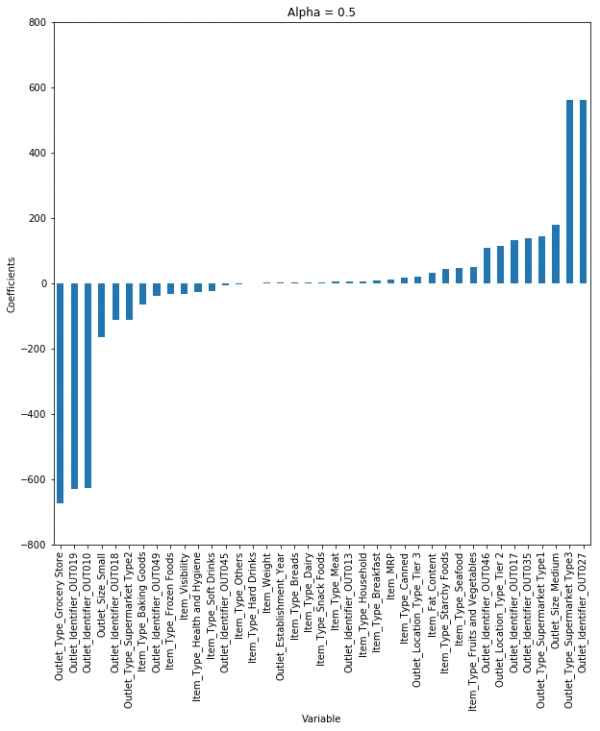


보시는 것과 같이 alpha가 커지면 커질수록 계수의 크기는 줄어들게 됩니다. 거의 0과 가까운 크기로요. 하지만 각각의 적용 alpha에 따른 R-square값은, alpha가 0.05일 때 maximum임을 알 수 있습니다. 이 결과가 시사하는 바는 우리는 값의 범위를 반복하면서 가장 낮은 오류를 산출하도록 현명히 접근해야 한다는 것입니다.
수학적 표현
지금까지 구현하는 법을 대충 알았으니, 수학적으로 한 번 살펴 보겠습니다. 지금까지 우리가 시도하려던 것은 cost function을 최소화하여 예측된 값이 원하는 결과와 가장 유사하도록 산출하는것이었습니다.
이제 ridge regression의 cost function을 살펴봅시다.

눈치 채셨겠지만, 이전 선형회귀에서와의 다른 점은 penalty항이라는 추가 항을 만나게 됩니다. 여기에서의 λ는 ridge function의 alpha값입니다. 따라서 alpha값을 변경한다는 것은 penatly term을 제어하게 됨을 뜻하네요. alpha값이 크면 클수록 penaly 또한 커지게 되면서 계수의 크기가 줄어듭니다. 이는 변수를 축소하면서 다중공선성(multicollinearity)를 방지하는데 쓰입니다.
중요 포인트
ㆍparmeters를 축소하는 작업은 다중공선성 방지에 가장 많이 쓰입니다.
ㆍ계수 축소에 의해 모델의 복잡도를 줄입니다.
ㆍL2 regularization을 활용합니다.
이제 정규화를 사용하는 또 다른 유형의 회귀 모형을 알아봅시다.
12. Lasso Regression
LASSO(Least Absolute Shrinkage Selector Operator)는 ridge와 유사하지만 과연 어떤 점에서 차이가 있는지 살펴봅시다.

MSE와 R-square값을 보면 lasso model이 linear나 ridge보다 더 좋은 예측 성능을 보입니다. 마찬가지로 alpha값을 바꿔가면서, 계수에 어떤 영향을 미치는지 알아봅시다.
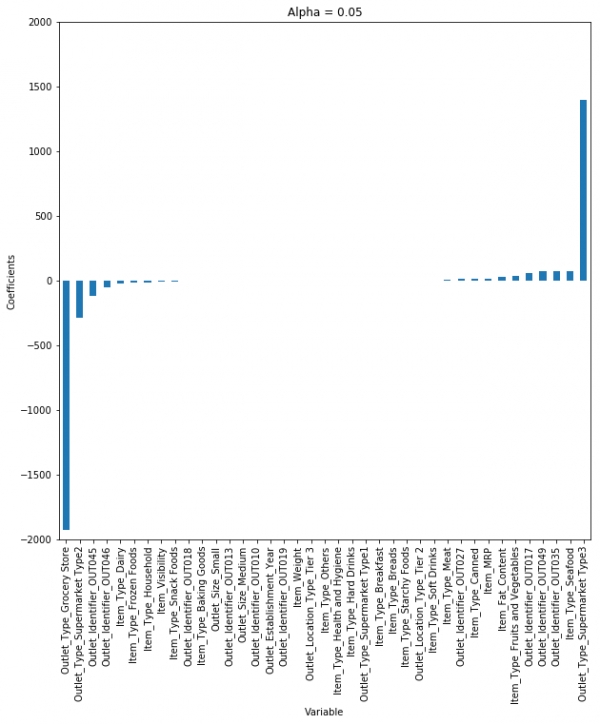

작은 알파값에서도 계수의 크기가 많이 줄어든 것을 볼 수 있습니다. plot만으로도 ridge와 lasso의 차이점을 아시겠나요?
알파값을 증가시키면, 계수는 거의 0에 가까워지지만 lasso의 경우 작은 알파값에도, 계수는 이미 완전한 0으로 줄어들었습니다.
따라서 lasso는 중요한 몇 개의 변수만 선택하고 다른 계수들은 0으로 줄입니다. 이 특징은 feature selection으로 알려져 있고, ridge regression의 경우 이 과정이 없습니다.
수학적으로 lasso와 ridge는 거의 유사하지만, theta제곱을 더하는(ridge의 방법론) 대신 theta의 절대값을 더하게(lasso의 방법론) 됩니다.

λ는 hypermeter입니다. Lasso에서의 alpha값인거죠.
여기서는 L1 regularization을 씁니다.
중요 포인트
ㆍL1 regularization을 활용합니다.
ㆍ변수를 자동으로 채택할 수 있어 일반적으로 많은 변수를 다룰 때 활용합니다.
이제 우리는 ridge와 lasso regression의 기본적인 이해를 하였습니다.
또 다른 예를 들어보겠습니다. 배운 것을 바탕으로 생각해보세요. 10,000개의 변수를 가지고 있는 큰 데이터셋이 있습니다. 그리고 이 변수들 중에는 서로 correlate되어있는 변수들이 존재합니다. 그렇다면 당신은 Ridge와 Lasso 중 어떤 예측 모형을 활용하겠습니까?
차근차근 살펴보죠.
1) ridge regression을 적용한다면 우리는 모든 변수를 가지고 오면서 계수값을 줄일 것입니다. 하지만 문제는 model이 아직까지도 복잡한 상태입니다. 1만 개의 변수를 그래로 유지하고 있는 것이지요. 이는 모델 성능 저하에 영향을 미칠 수 있습니다.
2) 그렇다면 Ridge 대신 Lasso를 적용해봅시다. Lasso에서의 가장 큰 문제는 변수들끼리 correlate하다면, Lasso는 단 한 개의 변수만 채택하고 다른 변수들의 계수는 0으로 바꿀 것입니다. 이는 정보가 손실됨에 따라 정확성이 떨어질 수 있습니다.
그렇다면 이 문제 해결 방법은 무엇일까요? 사실 또 다른 유형의 regression, Elastic Net Regression이 존재합니다. Elastic Net Regression은 Ridge와 Lasso의 하이브리드 형태라 볼 수 있습니다.
13. Elastic Net Regression
이론을 들어가기 전에 우선 파이썬으로 실행을 시켜보죠. 정말 Ridge와 Lasso보다 좋은 성능을 보일까요?

R-Square값이 나왔습니다. Ridge와 Lasso보다 낮네요. 왜 그럴까요?
이유는 elastic regression은 큰 데이터셋에서 가장 잘 작동하는데 우리가 적용해본 데이터셋은 많은 변수를 가지고 있지 않아서입니다.
여기서 우리는 alpha와 l1_ratio라는 두 개의 parameter를 가지고 있습니다. elastic net은 어떻게 작동하고, Ridge와 Lasso랑은 무슨 차이를 보이는지 알아봅시다.
Elastic net은 L1, L2 regularization의 조합입니다. 따라서 elastic net을 안다면 파라미터를 조정함으로써 Ridge와 Lasso도 구현할 수 있습니다. L1, L2 penaly term을 쓴다 하였으니 방정식은 다음과 같겠지요?

그렇다면 L1, L2 penaly term을 조절하기 위해 람다를 어떻게 조정해야 할까요?
예시를 들며 이해해보겠습니다.
당신은 연못에서 물고기를 잡으려 합니다. 그리고 당신은 그물을 가지고 있다면 이제 어떻게 해야할까요? 그냥 무작정 그물을 던지실 건가요? 아니죠. 당신은 한 마리의 물고기가 헤엄칠 때까지 기다렸다가 그 쪽으로 그물을 던져 나머지 물고기들도 잡을 것입니다. 그들 서로가 상관관계가 있다하더라도, 우리는 여전히 전체 그룹을 바라보고 싶어합니다.
Elastic regression도 이와 비슷하게 작동합니다. 예를 들어 우리는 일련의 상관된 독립 변수를 가지고 있다고 해봅시다. 그리고 elastic net은 이러한 상관된 변수로 구성된 그룹을 형성합니다. 이제 이 그룹의 변수 중 하나가 강력한 예측 변수(종속 변수와 강한 관계가 있음을 의미)가 있다면 이 전체 그룹을 model building에 포함시킵니다.
왜냐구요? 같은 그룹 내에 속하면서도 강력한 예측 변수 하나가 아닌 그 외 변수들을 모두 제거하면(Lasso가 행하는 방법처럼요.) 해석에 있어 정보 손실이 발생하여 결과적으로 모델 성능은 떨어지게 됩니다.
위의 코드를 보면 우리는 model을 정의할 때, alpha와 l1_ratio도 정의해야 합니다. alpha와 l1_ratio는 당신이 L1, L2 페널티를 따로 제어하고 싶다면 그에 맞게 설정하면 되는 매개 변수입니다.
이렇게 표현될 수 있습니다.
Alpha = a + b and l1_ratio = a / (a+b)
a와 b는 L1과 L2 term에 따른 가중치입니다. 따라서 우리가 alpha와 L1_ratio를 바꾼다면 L1과 L2의 trade off를 조정하면서 a와 b의 값이 정해질 것입니다.
a * (L1 term) + b* (L2 term)
alpha (or a+b)가 1이라고 가정했을 때, 다음과 같은 케이스를 생각해봅시다.
ㆍ만일 l1_ratio가 1이라면, a가 1이고 b가 0일때만 가능합니다. (위의 공식을 참고하십시오.) 따라서 이는 lasso penalty와 동일합니다.
ㆍ이와 비슷하게 만일 l1_ratio이 0이라면, a = 0을 의미합니다. 이는 ridge penalty와 같구요.
ㆍl1_ratio가 0과 1사이라면 penalty는 ridge와 lasso의 combination인 것입니다.
이제 alpha와 l1_ratio를 바꿔가며 이에 따라 계수가 어떻게 변하는지 이해해봅시다.


이제 우리는 ridge, lasso, elastic net regression의 기본적인 이해를 하였습니다. 그러나 이 과정에서 L1과 L2라는 용어(정규화의 유형)가 나왔습니다. 정리하자면 lasso와 ridge는 각각 L1과 L2 regularization의 직접적인 적용입니다.
*본 글은 https://www.analyticsvidhya.com/blog/2017/06/a-comprehensive-guide-for-linear-ridge-and-lasso-regression/의 일부분을 번역+약간의 의역을 하였습니다. 중간중간 저의 개별적인 설명은 파란색 글씨로 써두었습니다.
<외부 기고 콘텐츠는 이웃집과학자 공식 입장과 다를 수 있습니다>
월급쟁이(hwpark0502@gmail.com)
늘 재밌게 살고싶은 월급쟁이의 데이터 이야기
원문 출처 : https://brunch.co.kr/@itschloe1/11
