최근 다양한 분야에서 인공지능 심층 학습(딥러닝) 기술을 활용한 서비스가 급속히 증가하고 있죠. GPT와 같은 거대 언어 모델을 훈련하기 위해서는 수백 대의 GPU와 몇 주 이상의 시간이 필요합니다. 따라서, 심층신경망 훈련 비용을 최소화하는 방법 개발이 절실한데요.
KAIST 전산학부 이재길 교수 연구팀이 심층신경망 훈련 비용을 최소화할 수 있도록 훈련 데이터의 양을 줄이는 새로운 데이터 선택 기술을 개발했다고 2일 밝혔습니다.

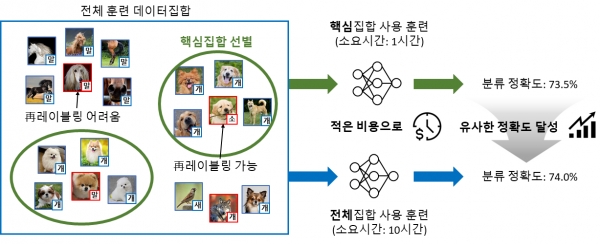
일반적으로 대용량의 심층 학습용 훈련 데이터는 레이블 오류(예를 들어, 강아지 사진이 `고양이'라고 잘못 표기되어 있음)를 포함합니다. 최신 인공지능 방법론인 재(再)레이블링(Re-labeling) 학습법은 훈련 도중 레이블 오류를 스스로 수정하면서 높은 심층신경망 성능을 달성합니다. 그런데, 레이블 오류를 수정하기 위한 추가적인 과정들로 인해 훈련에 필요한 시간이 더욱 증가한다는 단점이 있습니다. 한편 막대한 훈련 시간을 줄이려는 방법으로 중복되거나 성능 향상에 도움이 되지 않는 데이터를 제거해 훈련 데이터의 크기를 줄이는 핵심 집합 선별(coreset selection) 방식이 큰 주목을 받고 있습니다. 그러나 기존 핵심 집합 선별 방식은 훈련 데이터에 레이블 오류가 없다고 가정한 표준 학습법을 위해 개발됐고, 재레이블링 학습법을 위한 핵심 집합 선별 방식에 관한 연구는 부족한 실정입니다.
이재길 교수팀이 개발한 기술은 레이블 오류를 스스로 수정하는 최신 재레이블링 학습법을 위해 핵심 집합 선별을 수행하여 심층 학습 훈련 비용을 최소화할 수 있도록 해주는데요. 따라서, 레이블 오류가 포함된 현실적인 훈련 데이터를 지원하므로 실용성이 매우 높습니다.
또한 이 교수팀은 특정 데이터의 레이블 오류 수정 정확도가 해당 데이터의 이웃 데이터의 신뢰도와 높은 상관관계가 있음을 발견했습니다. 즉, 이웃 데이터의 신뢰도가 높으면 레이블 오류 수정 정확도가 커지는 경향이 있습니다. 이웃 데이터의 신뢰도는 심층신경망의 충분한 훈련 전에도 측정할 수 있으므로, 각 데이터의 레이블 수정 가능 여부를 예측할 수 있게 되는데요. 연구팀은 이러한 발견을 기반으로 전체 훈련 데이터의 총합 이웃 신뢰도를 최대화하는 데이터 부분 집합을 선별해 레이블 수정 정확도와 일반화 성능을 최대화하는 `재레이블링을 위한 핵심 집합 선별'을 제안했습니다. 총합 이웃 신뢰도를 최대화하는 부분 집합을 찾는 조합 최적화 문제의 효율적인 해법을 위해 총합 이웃 신뢰도를 가장 증가시키는 데이터를 차례차례 선택하는 탐욕 알고리즘(greedy algorithm)을 도입했습니다.
연구팀은 이미지 분류 문제에 대해 다양한 실세계의 훈련 데이터를 사용해 방법론을 검증했는데요. 그 결과, 레이블 오류가 없다는 가정에 따른 표준 학습법에서는 최대 9%, 재레이블링 학습법에서는 최대 21% 최종 예측 정확도가 기존 방법론에 비해 향상되었습니다. 그리고 모든 범위의 데이터 선별 비율에서 일관되게 최고 성능을 달성했습니다. 또한, 총합 이웃 신뢰도를 최대화한 효율적 탐욕 알고리즘을 통해 기존 방법론에 비해 획기적으로 시간을 줄이고 수백만 장의 이미지를 포함하는 초대용량 훈련 데이터에도 쉽게 확장될 수 있음을 확인했습니다.
제1 저자인 박동민 박사과정 학생은 "이번 기술은 오류를 포함한 데이터에 대한 최신 인공지능 방법론의 훈련 가속화를 위한 획기적인 방법ˮ 이라면서 "다양한 데이터 상황에서의 강건성이 검증됐기 때문에, 실생활의 기계 학습 문제에 폭넓게 적용될 수 있어 전반적인 심층 학습의 훈련 데이터 준비 비용 절감에 기여할 것ˮ 이라고 밝혔습니다.
연구팀을 지도한 이재길 교수도 "이 기술이 파이토치(PyTorch) 혹은 텐서플로우(TensorFlow)와 같은 기존의 심층 학습 라이브러리에 추가되면 기계 학습 및 심층 학습 학계에 큰 파급효과를 낼 수 있을 것이다ˮ고 말했다.
연구 결과는 국제학술대회 `신경정보처리시스템학회(NeurIPS) 2023'에서 올 12월 발표될 예정입니다.
논문명 : Robust Data Pruning under Label Noise via Maximizing Re-labeling Accuracy
#용어설명
[1] 심층 학습(deep learning): 심층신경망을 훈련하여 예측 모델로 활용하는 방식 전반을 가리킨다.
[2] 再레이블링(Re-labeling): 훈련 데이터에 존재하는 레이블 오류를 심층신경망 훈련 과정 중 스스로 자동으로 수정하여 최종 심층신경망 모델 성능을 향상하는 최신 인공지능 학습 방법론이다. 대표적인 방법론으로는 ICLR 2020 국제학술대회에 발표된 DivideMix 방법론이 있다.
[3] 핵심집합 선별(coreset selection): 심층신경망 모델 성능을 최대한 유지하도록 훈련 데이터의 일부를 선택하여 훈련 데이터의 크기를 줄임으로써 심층신경망 훈련을 가속하는 방식이다.
[4] 탐욕 알고리즘(greedy algorithm): 최적해를 구하는 데에 사용되는 근사적인 방법으로, 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식이다.
